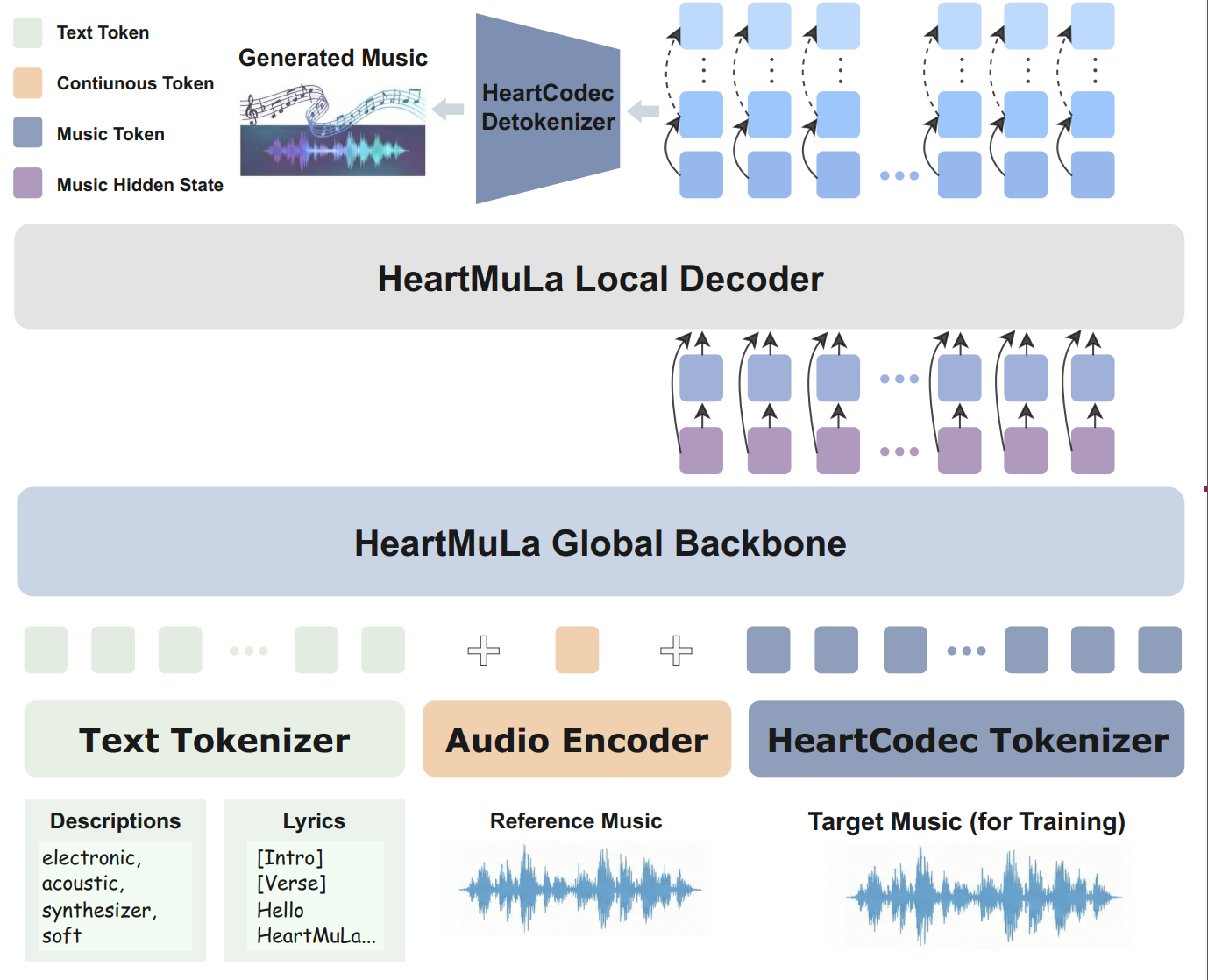
We present a family of open-source Music Foundation Models designed to advance large-scale music understanding and generation across diverse tasks and modalities. Our framework consists of four major components:
- HeartCLAP: an audio–text alignment model that establishes a unified embedding space for music descriptions and cross-modal retrieval.
- HeartCodec: a low-frame-rate (12.5 Hz) yet high-fidelity music codec tokenizer that captures long-range musical structure while preserving fine-grained acoustic details and enabling efficient autoregressive modeling.
- HeartTranscriptor: a robust lyric recognition model optimized for real-world music scenarios.
- HeartMuLa: an LLM-based song generation model capable of synthesizing high-fidelity music under rich, user-controllable conditions. HeartMuLa supports multi-conditional music creation with inputs including textual style descriptions, lyrics, and reference audio
In addition, it provides two specialized modes:
- fine-grained musical attribute control, which allows users to specify the style of different song sections (e.g., intro, verse, chorus) using natural language prompts.
- short, engaging music generation, which is suitable as background music for short videos.
Together, this suite of models forms an extensible open-source ecosystem that unifies music understanding, alignment, and controllable generation. We expect these foundation models to serve as strong baselines for future research and to facilitate practical applications in multimodal content production.